I was thinking less like a manager and more like a nerd. Are there pieces of code that are verily heavily tested (more tests, more lines in the tests) vs others that aren’t?
Because the very heavily tested ones (if there are any) would be interesting to look at. Probably solving some cool technical problem then.
Vs scaffolding code such as “read a command like option”. Which is kinda boring.
I’ve seen coverage reports that tells you how many times a row was ran during the tests, but that can be skewed by things such as loops.
Either way, I just got curious as curl is a fairly unusual piece of software and quite interesting in many ways beyond “it’s one heck of a useful tool”:)

Stefan Eissing
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Stefan Eissing • • •Stefan Eissing
in reply to daniel:// stenberg:// • • •Drew Hays
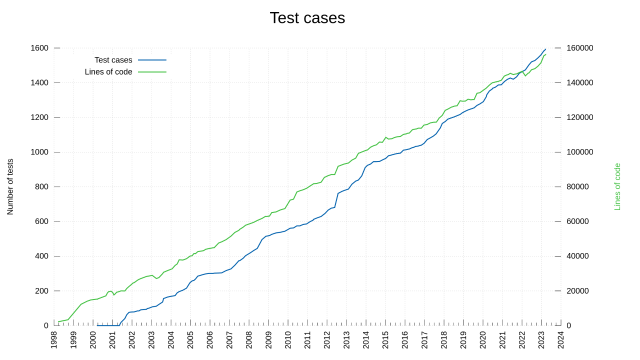
in reply to daniel:// stenberg:// • • •for like half a second, I thought this chart showed that the number of lines per test was roughly 1:1.
(That being said, looks like it at least scales somewhat linearly together.)
daniel:// stenberg://
in reply to Drew Hays • • •Gen X-Wing
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Gen X-Wing • • •Gen X-Wing
in reply to daniel:// stenberg:// • • •I was thinking less like a manager and more like a nerd. Are there pieces of code that are verily heavily tested (more tests, more lines in the tests) vs others that aren’t?
Because the very heavily tested ones (if there are any) would be interesting to look at. Probably solving some cool technical problem then.
Vs scaffolding code such as “read a command like option”. Which is kinda boring.
So just out of pure childlike curiousness :)
daniel:// stenberg://
in reply to Gen X-Wing • • •Gen X-Wing
in reply to daniel:// stenberg:// • • •I’ve seen coverage reports that tells you how many times a row was ran during the tests, but that can be skewed by things such as loops.
Either way, I just got curious as curl is a fairly unusual piece of software and quite interesting in many ways beyond “it’s one heck of a useful tool”:)
daniel:// stenberg://
in reply to Gen X-Wing • • •