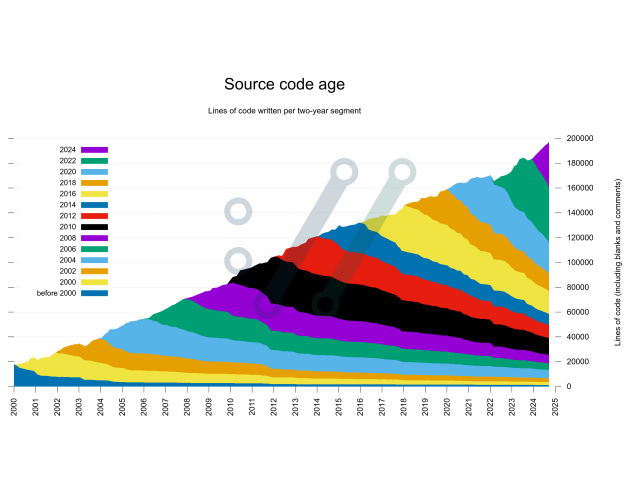
I think this one turned out to be the most informative one, or at least it piques my curiosity the most.
I think I'll try following along this graph with curl's version history at hand. For example, I now wonder what kind of refactoring happened around late 2011 - the older code amount drops rather sharply there :)
Oh this is really nice! You've inspired me to generate this for the Linux kernel. The git blames are running now... I parallelized it, but it's still going to take a while! :)
@hikhvar @dascandy Yeah, it's not as steep as with curl, but I'm starting to see it getting deeper with each segment. The 2016-2018 segment seems to eat into prior areas much more than the other year segments.
@hikhvar @dascandy I'm curios to see how much of what's left from "start of git history" in Linux is blank lines and comments. :) I'll need a whole new scanner for that. :P
@kurtseifried @hikhvar @dascandy Yeah, once this finishes I'm going to rework the caching and also store paths. Then I can re-run it with arbitrary path filters. The counting phase is fast. The blame phase is sloooow. 😅
and yet it runs the simplest form of blame. It could be argued that blame -CCC would give the more "right" info, but that's just so slow it's unbearable to use for this
@pierstoval cool, just ask if there's anything I can help you with. You might spot that I have a way to list all tags and I get the age of the project at those moments in time. If you have tags like that, you can do it the same way otherwise you need to figure out a different way to identify snapshot moments.
I got caught up in many things so I didn't have time to continue, but I'll certainly work on it during the next days! I'll keep you in touch, in case you're interested :)
I'm interested! If it helps, @kees made a port of the script over to python to make it perform better on larger code bases like the Linux kernel: github.com/kees/kernel-tools/t…
@pierstoval each line is a date and then line number counters for all the different time "slots" separated with semicolons, so that looks like perfectly fine output
Really the best visualization of this dataset so far!
I find it confusing that only even years like 2000, 2002, etc. are listed. Did you skip every 2nd year? If data for each two years is accumulated please write "2000-2001" in the key.
@dboehmer I wanted to keep the labels simple to reduce the amount of text, as it quickly becomes "heavy" otherwise. But yeah, I'll think of how to improve it.
a) write "2000 f." for 2000–2001 like common for giving page numbers in citations. (I just learned that "f." is for giving someone’s birthdate in Swedish 😁 ) en.wiktionary.org/wiki/f.#Adje…
b) Use "≤" or "≥" mathematical operators. As the key is most probably read from the top to the bottom maybe give the lower number year instead like - ≥ 2023 - ≥ 2021 - ≥ 2019 - … - < 2000
You’re so quick! I find this better than take 4, for sure.
If you want to minimize text space I’d consider this the optimal solution.
But to be honest I think it’s a bit too technical even—for software people. it takes a moment to understand this means each color represents two years …
More than ½ h after posting my suggestions I tend to think option C (that I added to the post) might be the most common notation: just "2023/24". Don’t you think? At least Germans use that a lot.
@dboehmer unfortunately I think that version gets too messy, probably because too many numbers. Without being crystal clear what it means. I think I'll stick with the ≥ for now.
@dboehmer for me, reading the graph part makes everything very clear. Like, the year number is just a point in time, at the transition between two years (e. g. black covers 2010-2012).
It would also be possible to work with dashes, like saying "up to 2002", though that needs a different numbering then:
It might be interesting to see this with log scale on y axis and, if those lines seem to decrease roughly linearly, to compare how halflifes change over time.

naught101
in reply to daniel:// stenberg:// • • •iliazeus
in reply to daniel:// stenberg:// • • •I think this one turned out to be the most informative one, or at least it piques my curiosity the most.
I think I'll try following along this graph with curl's version history at hand. For example, I now wonder what kind of refactoring happened around late 2011 - the older code amount drops rather sharply there :)
Urix Turing
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Urix Turing • • •daniel:// stenberg://
in reply to daniel:// stenberg:// • • •this is the version I'll make appear in the curl dashboard, starting tomorrow
curl.se/dashboard.html
curl - Project status dashboard
curl.sePeter Bindels
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Peter Bindels • • •Christoph Petrausch
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Christoph Petrausch • • •@hikhvar @dascandy
extract the data using git blame => github.com/curl/stats/blob/mas…
render the graph from the data the script generated using gnuplot => github.com/curl/stats/blob/mas…
stats/codeage.pl at master · curl/stats
GitHubKees Cook (old account)
in reply to daniel:// stenberg:// • • •Kees Cook (old account)
in reply to Kees Cook (old account) • • •daniel:// stenberg://
in reply to Kees Cook (old account) • • •Kees Cook (old account)
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Kees Cook (old account) • • •Christoph Petrausch
in reply to daniel:// stenberg:// • • •Kees Cook (old account)
in reply to Christoph Petrausch • • •@hikhvar @dascandy Yeah, it's not as steep as with curl, but I'm starting to see it getting deeper with each segment. The 2016-2018 segment seems to eat into prior areas much more than the other year segments.
I'm so impatient! Blame, git, blame! ;)
Christoph Petrausch
in reply to Kees Cook (old account) • • •Kees Cook (old account)
in reply to Christoph Petrausch • • •daniel:// stenberg://
in reply to Kees Cook (old account) • • •Kees Cook (old account)
in reply to daniel:// stenberg:// • • •kernel-tools/stats at trunk · kees/kernel-tools
GitHubdaniel:// stenberg:// reshared this.
kurtseifried
in reply to Kees Cook (old account) • • •Kees Cook (old account)
in reply to kurtseifried • • •daniel:// stenberg://
in reply to Kees Cook (old account) • • •Kees Cook (old account)
in reply to Kees Cook (old account) • • •daniel:// stenberg://
in reply to Kees Cook (old account) • • •Alex Rock
in reply to daniel:// stenberg:// • • •How did you gather the data to generate this graph?
This would be very helpful for some respositories 🎉
daniel:// stenberg://
in reply to Alex Rock • • •@pierstoval git blame is our friend. This is my (fairly small) perl script that extracts all the data:
github.com/curl/stats/blob/mas…
stats/codeage.pl at master · curl/stats
GitHubAlex Rock
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Alex Rock • • •Alex Rock
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Alex Rock • • •daniel:// stenberg://
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to daniel:// stenberg:// • • •Alex Rock
in reply to daniel:// stenberg:// • • •Thanks, did that, also removed the "print cache" statement.
I'll make a fork in order to simplify reviewing it 👍
daniel:// stenberg://
in reply to Alex Rock • • •Alex Rock
in reply to daniel:// stenberg:// • • •Yep, it's 20 years old and has like thirty thousand commits, might take a while indeed :)
Here's the current diff: github.com/Pierstoval/stats/pu…
It's not gathering data yet, I'm on it :)
Custom usage by Pierstoval · Pull Request #1 · Pierstoval/stats
GitHubdaniel:// stenberg://
in reply to Alex Rock • • •Alex Rock
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Alex Rock • • •kernel-tools/stats at trunk · kees/kernel-tools
GitHubAlex Rock
in reply to daniel:// stenberg:// • • •Alex Rock
in reply to daniel:// stenberg:// • • •I had some time this evening to check it out, turns out the very little things I did allow me to have an output, but it looks like this:
❯ perl stats/codeage.pl
2015-09-15;0;0;0;0;0;0;0;0;0;0;0;0;0;0
2015-11-27;0;0;0;0;0;0;0;0;0;0;0;0;0;0
2016-04-01;0;0;0;0;0;0;0;0;0;0;0;0;0;0
2016-04-11;0;0;0;0;0;0;0;0;0;0;0;0;0;0
2016-07-19;0;0;0;0;0;0;0;0;0;0;0;0;0;0
2016-07-27;0;0;0;0;0;0;0;0;0;0;0;0;0;0
2016-11-15;0;0;0;0;0;0;0;0;0;0;0;0;0;0
I'm trying to look where the 0s come from
Alex Rock
in reply to Alex Rock • • •If I remove the "if" statement in the "sub show" function, apparently it gives me an output, though very slowly as you mentioned before:
❯ perl stats/codeage.pl
2015-09-15;0;0;0;12287;29598;54171;113862;150511;178495;178495;178495;178495;178495;178495
2015-11-27;0;0;0;12287;29337;53754;113326;149811;187962;187962;187962;187962;187962;187962
I don't know if these kind of data are relevant, but it's another output.
I pushed it to my fork, on the PR in an earlier post :)
daniel:// stenberg://
in reply to Alex Rock • • •daniel:// stenberg://
in reply to daniel:// stenberg:// • • •Alex Rock
in reply to daniel:// stenberg:// • • •It seems to be okay when using @kees's scripts! The automatic cache definitely helps a lot 🎉
I will let it run through all day and wait for more details 👌
daniel:// stenberg://
in reply to Alex Rock • • •daniel:// stenberg://
in reply to daniel:// stenberg:// • • •my current look
See the fc instructions per plot in github.com/curl/stats/blob/mas…
stats/codeage.plot at master · curl/stats
GitHubdaniel:// stenberg://
Unknown parent • • •Manvir Clair
in reply to daniel:// stenberg:// • • •Jean Luc am Grimmsten
in reply to daniel:// stenberg:// • • •Daniel Böhmer
in reply to daniel:// stenberg:// • • •Really the best visualization of this dataset so far!
I find it confusing that only even years like 2000, 2002, etc. are listed. Did you skip every 2nd year? If data for each two years is accumulated please write "2000-2001" in the key.
daniel:// stenberg://
in reply to Daniel Böhmer • • •Daniel Böhmer
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Daniel Böhmer • • •Daniel Böhmer
in reply to daniel:// stenberg:// • • •May a make two (edit: three) suggestions:
a) write "2000 f." for 2000–2001 like common for giving page numbers in citations.
(I just learned that "f." is for giving someone’s birthdate in Swedish 😁 )
en.wiktionary.org/wiki/f.#Adje…
b) Use "≤" or "≥" mathematical operators. As the key is most probably read from the top to the bottom maybe give the lower number year instead like
- ≥ 2023
- ≥ 2021
- ≥ 2019
- …
- < 2000
c) short form 2000/01 to 2023/24
f. - Wiktionary, the free dictionary
Wiktionarydaniel:// stenberg://
in reply to Daniel Böhmer • • •Daniel Böhmer
in reply to daniel:// stenberg:// • • •You’re so quick! I find this better than take 4, for sure.
If you want to minimize text space I’d consider this the optimal solution.
But to be honest I think it’s a bit too technical even—for software people. it takes a moment to understand this means each color represents two years …
More than ½ h after posting my suggestions I tend to think option C (that I added to the post) might be the most common notation: just "2023/24". Don’t you think? At least Germans use that a lot.
daniel:// stenberg://
in reply to Daniel Böhmer • • •sirjofri
in reply to daniel:// stenberg:// • • •@dboehmer for me, reading the graph part makes everything very clear. Like, the year number is just a point in time, at the transition between two years (e. g. black covers 2010-2012).
It would also be possible to work with dashes, like saying "up to 2002", though that needs a different numbering then:
- 2000
- 2002
- 2004
...
daniel:// stenberg://
Unknown parent • • •robryk
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
Unknown parent • • •