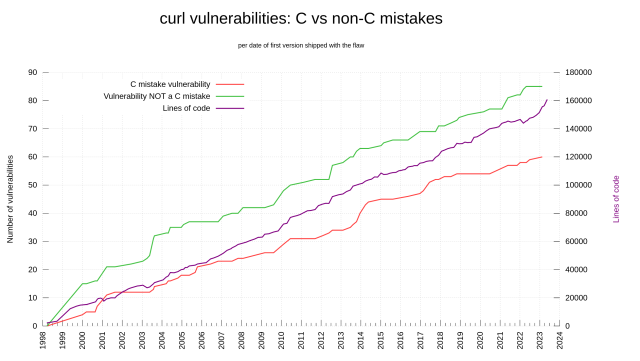
The #curl graph we always get to debate over. Number of *C mistakes* vs *non-C mistakes* among the existing 145 reported vulnerabilities. Updated with the latest 4 reports, and the LOC graph added as a comparison.
how do you distinguish "C mistakes" from "non-C mistakes"? Just memory safety, or also considering better abstractions that would've been used in anything other than a line-by-line translation?
The sharp uptick in 2014 is interesting. Was there a particular effort that year that exposed so many (valgrind?), or just the randomness of data? I didn't see you discuss the history in your blog post.
(These reports are a real asset. Thank you for so much transparency and helpful data.)
@cocoaphony the graph shows when the flaws were introduced, not found. I really don't know how it happened so much in that particular period. We have adjusted and improved internals since then, which possibly have helped.
@ArneBab clearly the c mistake share has decreased significantly the last two years. I suppose we will learn if this was just a fluke or something real as we go forward!

Lambda
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to Lambda • • •I qualify "C mistakes" to be one of: OVERFLOW, OVERREAD, DOUBLE_FREE, USE_AFTER_FREE, NULL_MISTAKE or UNINIT.
They have all been manually assessed by me, so there's a of course a risk of mistakes in there.
My thinking has been to identify problems that *likely* would not have happened if we had not used C.
Troed Sångberg
in reply to daniel:// stenberg:// • • •Rob Napier
in reply to daniel:// stenberg:// • • •The sharp uptick in 2014 is interesting. Was there a particular effort that year that exposed so many (valgrind?), or just the randomness of data? I didn't see you discuss the history in your blog post.
(These reports are a real asset. Thank you for so much transparency and helpful data.)
daniel:// stenberg://
in reply to Rob Napier • • •daniel:// stenberg://
Unknown parent • • •daniel:// stenberg://
Unknown parent • • •brk, a.k.a. @evanrichter
in reply to daniel:// stenberg:// • • •daniel:// stenberg://
in reply to brk, a.k.a. @evanrichter • • •Alexander Shendi
in reply to daniel:// stenberg:// • • •It would be interesting to know what distinguishes 'C' from 'non C' mistakes.
My summary of the graph:
* 'C mistakes' account for roughly 2/3 of all nistakes.
* Both 'C' and 'non C' mistakes strongly correlated with LOC.
daniel:// stenberg://
in reply to Alexander Shendi • • •Alexander Shendi
in reply to daniel:// stenberg:// • • •True, my mistake. Now, what counts as 'C' mistake? Links or references to papers ok.
TIA.
daniel:// stenberg://
in reply to Alexander Shendi • • •half of curl’s vulnerabilities are C mistakes | daniel.haxx.se
daniel.haxx.seAlexander Shendi
in reply to daniel:// stenberg:// • • •Thank you, very interesting.
The chart at:
daniel.haxx.se/blog/wp-content…
was what I wanted to know. I hope I haven't offended you, I just was looking for an opportunity to learn something.
ArneBab
in reply to daniel:// stenberg:// • • •In this graph it looks much more like the C vulnerabilities are stagnating than it sounds like in the article 2 years ago.
Thank you for sharing!
daniel:// stenberg://
in reply to ArneBab • • •ArneBab
in reply to daniel:// stenberg:// • • •