Repeated the #compression #benchmark with the same file on a beefier machine (AMD Ryzen 9 5950X), results are quite identical, except faster overall.
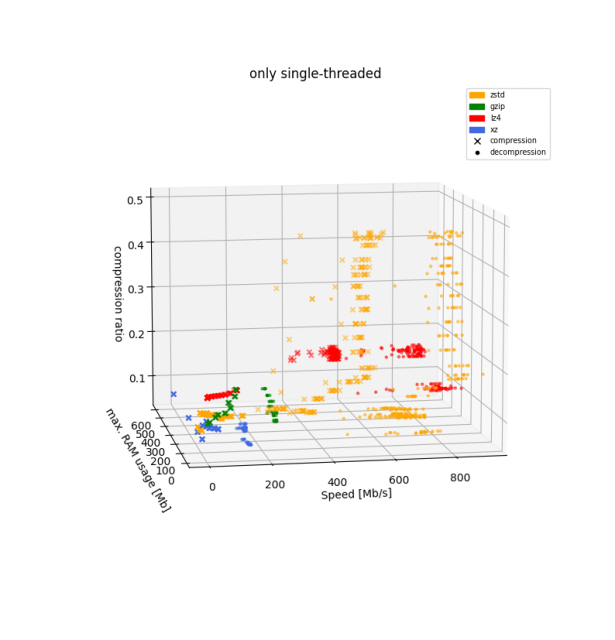
This plot is also interesting:
- #gzip and #lz4 have fixed (!) and very low RAM usage across levels and compression/decompression
- #xz RAM usage scales with the level from a couple of MBs (0) to nearly a GB (9)
- #zstd RAM usage scales weirdly with level but not as extreme as #xz