
Just realized: Whenever I read outrageous news about politics, my outrage comes second. First, my brain makes an attempt to find a perspective in which it might make sense to act like these morons do.
That‘s not healthy for my brain. But I‘ve trained myself so well that I can’t seem to unlearn the reflex.
And this is the main reason why I have to avoid news these days. Of course it’s also because of the helplessness and all the bad emotions. But mainly because „understanding“ causes damage to my brain and soul.






 - Link to source")




 with the date of the block... some seconds ago")
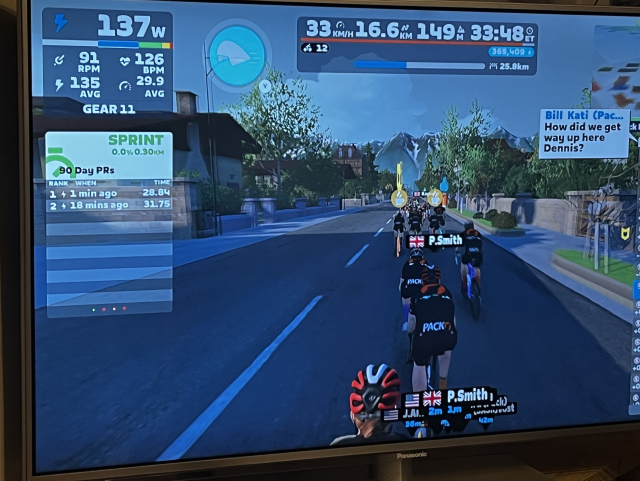
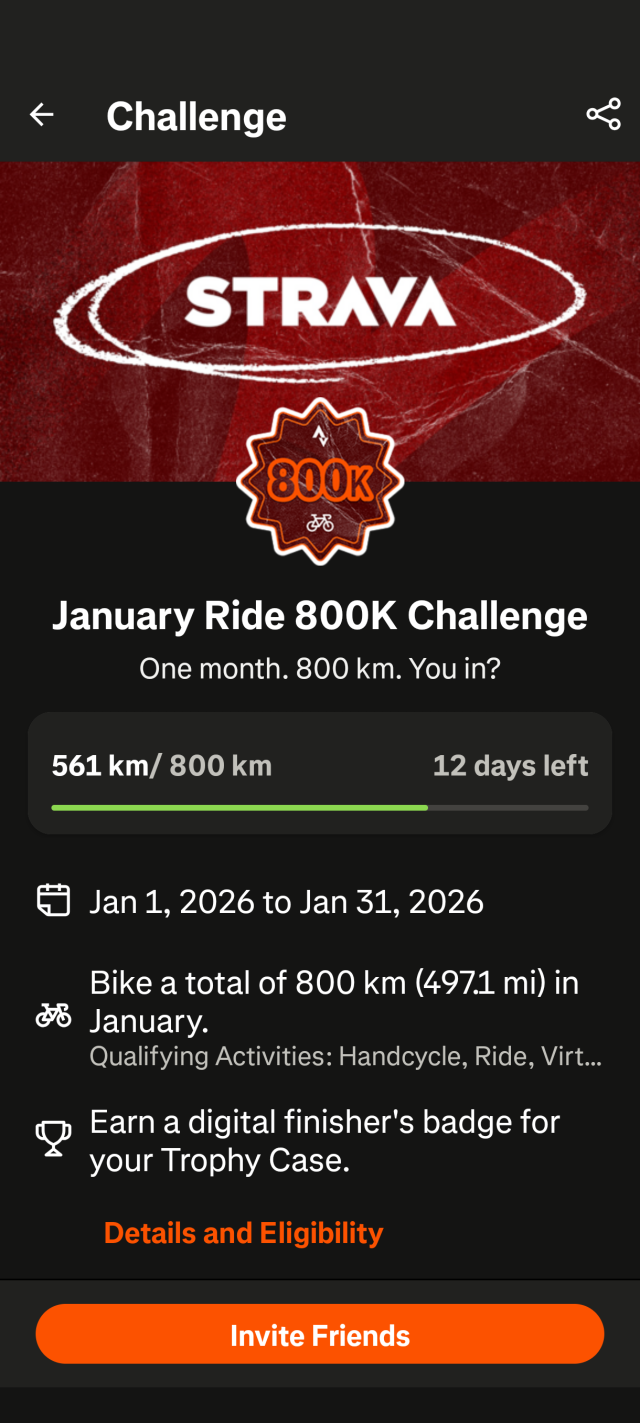
") )
)

")






 support by sascha-frinken · Pull Request #20343 · curl/curl")
 is the single largest stressor, leading to degradation rates up to twice that of the low power charging group (3.0% vs 1.5% per year).
Climate: Hot climates impose a penalty on battery life, with vehicles operating in hot conditions degrading 0.4% faster per year than those in mild climates.
Utilization: The increase in degradation from high daily use is a measurable but worthwhile trade-off for the gains in fleet productivity and ROI.
State of charge (SOC): For most EV use, there's no need to worry about avoiding fully charging or emptying the battery. Degradation only speeds up when vehicles spend over 80% of their total time at or near-full or nearly empty charge levels.")
")


feld
in reply to arosano 🇩🇰 🇮🇱 • • •this is an impossible problem to solve for everyone so it HAS to be configurable. Otherwise if you want to abuse people it's too easy.
*posts gore image*
#death #destruction #blood #murder #puppies
oh great someone wanted #puppies but not gore on their timeline, but now they get gore?