
Tilix: A Tiling Terminal Emulator With Bookmark Support linuxtoday.com/blog/tilix-a-ti…
reshared this



Having the computed value of CSS variable directly in the variable tooltip in @FirefoxDevTools is sooo good! Hope you'll enjoy this as much as I do, and be ready for more!
2 dead, 1 in critical condition as major fire burns in Old Montreal
cbc.ca/news/canada/montreal/fi…
Same slumlord as the 2023 fire in the old Montréal that also had death. Coincidence?
This month in Servo…
⬅️✍️ right-to-left layout
🔮📩 <link rel=prefetch>
🔡🎨 faster fonts and WebGPU
📂📄 better tabbed browsing
🤖📱 Android nightlies
More details → servo.org/blog/2024/10/03/this…
 and (BigUint64Array), and innerText and outerText")


datetime.date.today() - epoch
datetime.timedelta(days=20000)")
Installing Nextcloud on Ubuntu 24.04!
JayTheLinuxGuy shares an updated tutorial exploring how to host your own Nextcloud on your favorite VPS 🚀
👩🏼💻 A great weekend project!
reshared this
#Rechtsstaat #Asyl #Afghanistan
Ein Rechtsstaat darf Grenzen nicht pauschal auch für Opfer von Diktaturen + Verbrechern dicht machen.
Dies umso mehr, als sich Terrorismus so nicht verhindern lässt. Denn viele Terroristen radikalisieren sich erst bei uns, auch befördert durch Ausgrenzung.
Hey, people? MSN is a terrible news site that pretty much only reposts from other sources.
Link directly to those sources instead.
Also, it's run by robots;
Aufruf im Netz gefunden
Der "Comedian" Luke Mockridge plant morgen, am 05.10. um 20 Uhr, im Kulturforum (Gut Wienebüttel, 21339 Lüneburg) aufzutreten.
[...]
Wir haben keinen Bock, dass sich Täter und Ableisten Bühnen nehmen, andere ihnen eine Bühne bieten und sie ignorant abfeiern. Solidarisieren wir uns mit Betroffenen patriarchaler und ableistischer Gewalt!
Wir rufen dazu auf, den Auftritt zu blockieren. Dies ist ein autonomer Aufruf [...]
Unser Aufruf richtet sich nicht gegen den Kulturforum Lüneburg e.V., der sich von Mockridge distanziert, eine Stellungnahme vor dem Auftritt und Konsequenzen bei weiteren Grenzüberschreitungen ankündigt. Nehmt Rücksicht darauf. Trotzdem hätte Mockridge, schon vor den ableistischen Aussagen, nicht eingeladen werden dürfen.
Werdet aktiv! Schließt euch zusammen, seid kreativ, passt aufeinander auf!
#KeineBühneFürAbleismus
#LukeMockridge
#Lüneburg
#Ableismus
#FightAbleism

»Im schlimmsten Fall, so sehen es #Wanderwitz und seine Unterstützer, würde man das Verfahren vielleicht nicht ganz gewinnen, aber auch nicht verlieren. Mindestens ein paar besonders extreme Landesverbände würden dann verboten, im Antrag werden etwa Thüringen, Sachsen und Sachsen-Anhalt genannt. Außerdem würde der #AfD die staatliche Parteienfinanzierung entzogen. Davon sind sie überzeugt.«
Das ist doch was!
Dieser CDU-Mann treibt das AfD-Verbotsverfahren voran
spiegel.de/politik/deutschland… (S+)

„Langfristig gesehen seien Personen, denen Sanktionen auferlegt wurden, seltener erwerbstätig.“
taz.de/Sanktionen-fuer-Buerger…
Mehr ist dazu nicht zu sagen. Könnten wir bitte mit den Sanktionen aufhören? Sie sind nicht nur unmenschlich, sondern auch dumm.



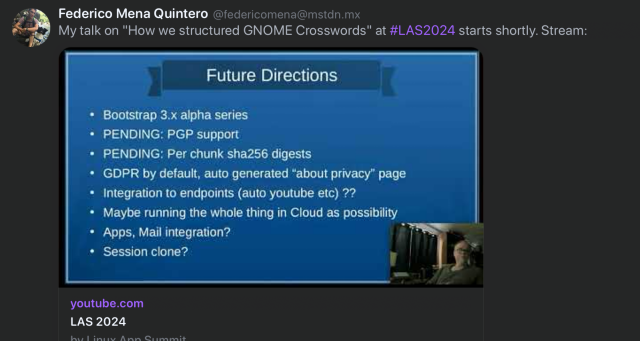
Still battling a bit of a cold and headache, but nonetheless let's try to do another Thunderbird live coding session
Sensitive content








")

Hubert Figuière
Unknown parent • • •