Yet another one study showing the stereotype threat does not exist. At this point the effect should be considered invalid and should not be used as an argument in any discussion (be it online or official).
Really sorry to be missing the Matrix Conference, but at least able to watch on the live stream!
DINUM’s Julie Ripa is giving a talk about everything Tchap, the French sovereign messenger based on @matrix and look at how PACKED the room is!


The future is now, and @matthew is giving us a glimpse at what to expect in the VERY short run.
Exciting to see MONTHS if not years of work fitting together




Watch The Matrix Conference's talks
The Matrix Conference is coming to Berlin, Germany on September 19–22, 2024.2024.matrix.org








Woo, getting ready to press the big "Go Live" button for the streams, as I see a @josh getting to his stage!
The excitement is real 🤩
Follow along at 2024.matrix.org/watch/!
Hey y'all. Drunk driving is whack. ESPECIALLY WHEN YOU RUN OVER LOCAL MUSICIANS WHO ARE WALKING HOME FROM THEIR BARTENDING GIG WHICH THEY HAVE TO DO BECAUSE WE DON'T VALUE WORKING MUSICIANS ENOUGH TO SUPPORT THEM IN A WAY THAT ALLOWS THEM TO FOCUS SOLELY ON THEIR MUSIC.
Anyway. Go support Luke Trimmer's Go Fund Me to help with his medical and recovery expenses.
And DON'T. FUCKING. DRINK. AND. DRIVE.

The great Pain au Chocolat / Croissant war has a winner at the venue. It indeed is a Pain au Chocolat



Hace más o menos una hora empecé a leer "Yo, robot" de Isaac Asimov, y ya voy en el capítulo cinco. Estoy alucinando con todo lo que estoy leyendo, y eso que nunca fui fan de la ciencia ficción más allá de la space opera.
👋 Hi, #scholars, tell us, why are you on #Mastodon?
🔍 We are researching how and why academics use Mastodon compared to other platforms. Is it key for #academic #discourse?
🔜 We'll launch our #research survey by mid-October, so stay tuned.
📣 Meanwhile: what features of Mastodon do you find most valuable for academic discourse?
And which other questions should we include in our research, you think?
#AcademicMastodon #AcademicChatter #OpenScience #SocialMedia
Vercel v dubnu updatoval ceniky. Misto tradicniho pomaleho utahovani sroubu to fakt napalil a zavedl "Edge Requests", za timto kryptickym popiskem se skryva jakykoli request. (cti: assety)
V EU za to platime $2.60/1M requestu.
Zjistil jsem to, kdyz nam Volebni Kalkulacka vesele napocitava 5.6M Edge Requestu za den. Jeste, ze nejsou prezidentske volby a senatori dodali odpovedi tak pozde!
Cas z Vercelu odejit.
Pro predstavu porovnani jednoho dne senatu a prezidenta.

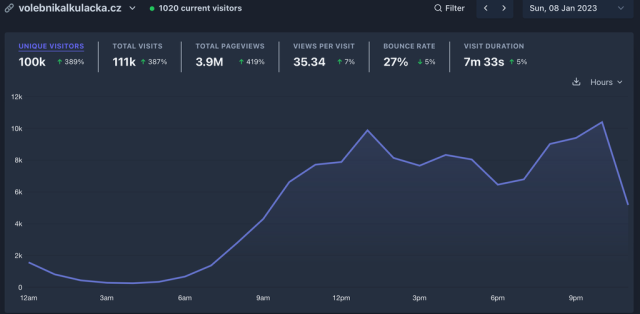
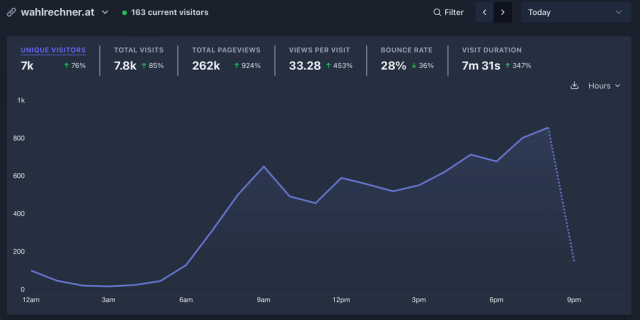
Pokud se dobře pamatuju, tak Vercel byla jen pěkně zabalená AWS Lambda.
Kdyby pomohla nějaká asistenci s nastavováním přímo na té lambdě, tak nabízím pomoc.
@verosk Diky, je to tak, sluzby Vercelu bezi nad AWS cloudem. Je to trochu komplikovanejsi a psat bych o tom moh cely den. Ale v zasade to tak jednoduche neni, Vercel ma custom runner, ktery je brutalne optimalizovany a nahradit se da spis na EC2/EKS nez Lambdy. Ale ztrati se tim veskera vyhoda, proc to takhle delam.
Jednoduchost a DX.
Budu to resit stejne jako to delam na Unreleased, oddelim do vlastni CDN vcesko, co pujde a tim snizim requesty.
buenos días desde la Administración Pública.
Por fin es viernes. Hoy tenemos: movidas varias con órganos colegiados, cuestiones sobre el plan de radón, y la memoria balance. Y aunque todavía no lo puedo decir, a lo largo de la mañana diré: chove en Santiago.
Another design session and then some initial coding for the next THunderbird live streaming.

If you're a #language nerd like I am, then you won't have missed the @mozilla #CommonVoice v19 #speech #dataset release - which now features 131 languages! Here's my #dataviz, done in @observablehq of the v19 #metadata coverage.
I've updated the visualisation this time around with human-readable language names instead of their ISO-639 or BCP-47 language codes to make it it easier to read.
There's some interesting observations:
▶ Catalan (ca) continues to be leader in terms of data - speaking volumes about the efforts to revitalise culture and language in Catalunya. It's also one of the few languages that has data for all age groups, particularly older speakers - this sort of data is missing for most other languages.
▶ Kiswahili (sw) is one of the languages where there is more data for female-identifying speakers than for male-identifying speakers ♀ - although Japanese (ja), Western Mari (mrj) and Luganda (lg) do pretty well here, too!
▶ Sentence domains can now be categorised, and although most new sentences are "general", Albanian (sq) has a lot of sentences related to law and government.
▶ Tsonga (ts), a Bantu language spoken in Southern Africa, has dethroned Icelandic (is) as the language with the highest average utterance duration. I don't know enough about Tsonga to speculate why - it's a somewhat agglutinative language, but many Tsonga works are generally short.
▶ Bengali / Bangla (bn) has a significant amount of data that is not yet validated, and therefore does not appear in training / dev / test splits. There is a similar case for many languages new to Common Voice - it takes time to validate.
▶ The language with the highest number of average contributions per speaker is Taita (dav), a Bantu language from Kenya.
What do you make of the data visualisation? Are there any other insights you can see?
Big thanks to the CV team for all their efforts - EM, Jessica Rose, Dmitrij Feller and Justin Grant.
Wissenschaftliche Fakten zu Accessibility Overlays gefällig?
@dnikub hat geforscht.
Hier gibt’s ihre Ergebnisse: youtube.com/watch?v=Atc5v64gqd…
Kelly Wickham
in reply to David Goldfield • • •